
opencv image stitching(panorama)
image stitching
1년 전쯤 CV를 공부하다가 작성한 내용이 생각나 다시 정리하여 본다.이하 내용은 개념 및 이론적인 내용보다는 코드를 설명이 대부분이다. 또한 하드 코딩 되어 있는 부분이 많아 좋은 코드라고 말하지는 못하겠다….
이후 내용은 opencv를 이용하여 3개의 이미지를 stitching하여 파노라마 사진처럼 만드는 내용이다. 각 이미지는 서로 다른 밝기 노출 시간등을 설정해주어 image stitching 시 blending이 잘일어나는지 확인하였다.
이후 내용의 진행 과정은 아래와 같다.
- 가운데 영상을 중심으로 Stitching
- opencv에서 제공하는 함수 warpPerspective 함수와 alpha blending 사용하여 stitching 진행
- 모든 영상이 잘림 없도록 영상 크기 설정
- findHomography 함수를 통해 구한 M(Homography) 수정을 통해 영상 translation 진행
- 겹치는 부분에서 영상의 자연스러운 블렌딩 처리
- eclipse mask를 통한 alpha blending 과 라플라시안, 가우시안 피라미드를 이용한 실험
시작하기 앞서 다음은 image stitching에 사용된 3장의 영상이다. Blending이 정확히 진행되었는지 확인하기 위하여 각사진의 밝기 등 세부 옵션을 다르게 하여 사진을 촬영하였다.

또한 고해상도 사진을 사용할 경우 연산 속도가 너무 오래 걸리기 때문에 해당 이미지의 사이즈를 잘 조절하자.
1 | |
stitching을 진행하기 위해서는 먼저 두 이미지간 matching feature를 찾아 주어야한다. 이하 코드는 opencv에서 제공하는 공식 문서에 명시 되어있는 feature matching과 이를 통한 Homography matrix를 구하는 코드이다.
1 | |
먼저 sift 알고리즘을 이용하여 rotation과 scale에 robust한 feature을 찾아준다. 이를 수행하는 함수는 detectAndCompute 함수이며 이미지와 마스크 값을 파라미터로 갖는다. 해당 함수는 이미지의 keypoint 와 keypoint에 대한 descriptor을 반환하여 준다. 이후 KDTree를 이용 가까운 점들을 찾아주고 해당 정보를 바탕으로 FLANN 기반 이미지 feature matching을 진행하여 준다.
1 | |
이후 이전에 찾은 정보를 바탕으로 KNN알고리즘을 통하여 세부 thresholding 값을 지정하며good feature들을 잡아낸 후 해당 feature들의 변환정도를 findHomography 함수가 계산하여 변환을 나타내는 3x3 Metrix를 반환해준다.

이제 구한 homography matrix를 이용하여 이미지를 stitching 하기 전 그대로 이미지를 stitching하면 합쳐진 이미지의 일부분이 잘리고 이후과정에 있어 연산이 너무 많다는 문제가 발생하며 다음과 같은 처리 후 image stitching을 진행해 주었다. (하드 코딩 되어있다….)
1 | |
따라서 이를 해결하기 위해 이미지를 적당한 translation을 진행해줄 필요가 있으며. 또한 이미지의 scale을 추가적으로 줄여 빠른 연산을 하기 위하여 M1_1에 더욱더 작은 scale이 적용되도록 정의하였으며 translation 관련해서는 휴리스틱한 방법으로 직접 값을 찾아 넣어주었다. 또한 행렬 연산의 특성상 단순히 행렬을 더하거나 빼는 것으로는 원하는 결과를 얻을 수 없기 때문에 numpy에서 제공하는 matmul 함수를 이용하여 두 행렬 연산을 진행해준다. 이렇게 얻은 행렬을 이용하여 두 이미지를 warpPerspective 함수에 넣어 이미지를 적당히 조절하여 주면 이제 두 이미지를 합치기 위해 동일한 배치상에 두는 것을 완료하였다.

이미지를 그냥 더하기 연산을 통하여 합치게 된다면 오버랩 되는 부분에 큰 값이 들어가 의도한 결과가 나오지 않기 때문에 블랜딩이 필요하다. 해당 예제에 경우 경계에 대한 blending이 가장 중요하기 때문에 이에 따른 alpha blending을 진행하는 것이 제일 적합하다고 판단된다. 따라서 먼저 alpha를 0.5로 하고 alpha blending을 진행한 결과 다음과 같은 결과를 얻을 수 있었다. 단순 합치는 것 보다는 훨씬 좋은 결과이지만 이미지 사이 경계가 전혀 자연스럽지 않다는 것을 알 수 있으며 구한 homography metrix가 완벽하지 않아 이미지 또한 완벽히 일치하지 않는 것을 확인 가능하다.

이러한 문제들을 해결하기 위해서 mask를 이용한 alpha blending을 진행할 필요가 있다. 먼저 가운데 이미지에 mask를 생성하는 것이 가장 효율적이기 때문에 가운데 이미지에 대하여 타원 모양에 마스크를 생성한후 blur 처리를 통하여 값이 퍼지는 효과를 구현하도록 하겠다. 또한 민들어진마스크도 img2 과 동일하게 wrapPerspective를 진행하여 주어야 한다.
1 | |
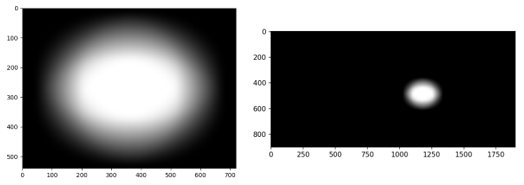
이제 다음과 같은 결과를 얻을 수 있으며 해당 결과를 alpha 값으로 사용하면 적당한 alpha blending을 적용할 수 있게 된다.
1 | |
Blending 전후 사진을 비교하여 본다면 크게 체감이 될 정도의 차이를 알 수 있다. 하지만 검은색 noise 또한 발생한 것을 알 수 있는데 들을 확인이 가능하다. 이러한 부분을 해결하기 위하여 다양한 시도를 해본 결과 가장 좋은 방법은 각 이미지를 blending 시 연선을 최저로 하기 위해 image2를 기준으로 한 하나의 mask가 아닌 각 blending 과정에서 다른 mask를 사용하여 진행 시 더욱 자연스러운 결과를 얻을 수 있었다. 두 가지 색의 원을 보면 훨씬 blending이 안정된 것을 알 수 있다. 다만 alpha blending의 특성상 alpha 값이 작아짐에 따라 일부 검은색 noise들을 완벽하게 지워주는 최적의 mask는 찾지 못하였다.

위 과정을 통해 얻은 최종 결과물이다. 처음 단순한 stitching을 진행한 것에 비해 매우 자연스러운 결과를 얻을 수 있었다. 다면 완벽한 blending이 진행되었다고 하기에는 alpha blending의 한계를 볼 수 있다.

추가 실험

노란 원에 해당하는 부분은 두 이미지가 겹치는 부분이 아니기 때문에 alpha blending이 적용되지 않는다. 그 결과 다소 부자연스러움이 느껴진다. 이를 해결하고 조금씩 있는 noise를 제거하기 위하여 이미지를 blur 처리한 후 Laplacian filter을 이용하여 처리하는 방안을 구상하였다. 해당 issue는 https://dsp.stackexchange.com/questions/3082/blending-artifacts-in-photo-stitching 에서도 확인이 가능하다. 명시되어 있는 몇 가지 해결책이 있지만 수업시간 학습한 가우시안 피라미드의 개념을 적용하고 싶어서 아래와 같은 과정으로 진행해 보았다.

앞서 말한것과 같은 과정을 진행하면 오른쪽과 같은 이미지를 얻을수 있으며. 기존 검은색 점 같은 noise들도 모두 사라진 것을 확인이 가능하다. 전체적인 색 대비는 거의 사라졌지만 전체적으로 너무 이미지의 대비가 흐려진 것을 확인가능하다. 따라서 해당 작업은 진행하지 않는 것이 적합하다고 판단하였다.
이 방법이 아니더라고 다양한 해결 방법을 시도하여 볼 수 있다.(딥러닝 관점에서 접근해도 좋을 듯)
코드개선
- 레퍼런스를 참조하여 기존 휴리스틱한 방식 개선
해당 링크를 참고하면 기존 휴리스틱 하게 matrix를 조절하여 사이즈를 정해준 부분을 개선하는 방안을 명시하여 준다.
1 | |
해당 링크에서 제공하는 위 코드를 사용하면 다음과 같은 결과를 얻는 것이 가능하다. 휴리스틱한 방법이 아닌 모든 이미지에 맞게 자동으로 변환된다는 점에서 큰 장점이 있으며 result[t[1]:h1+t[1], t[0]:w1+t[0]] = img1부분 대신 blending을 위와 같은 방식으로 구현한다면 모든 이미지에 꼭 맞는 결과를 얻을 수 있다. 하지만 비록 좋은 코딩이라고 말하기는 어렵지만 직접 구현한 코드가 있기 때문에 좀 더 직관적으로 이해가 가능한 직접 구현한 코드를 사용하였다.
Reference
-
opencv documentation
궁금한 점이 있다면 남겨주세요! 함께 고민해 보겠습니다.