Learning Continuous Image Representation with Local Implicit Image Function
이하 내용은 Learning Continuous Image Representation with Local Implicit Image Function 논문을 리뷰하여본 내용이며, 잘못 리뷰한 내용이 있을 수 있습니다! 의문점은 공유해주세요! 저도 고민해 보겠습니다.
산학 프로젝트 관련하여 implicit lidar network를 리뷰할 필요가 있었다. 해당 논문은 이 Liif에 attention 구조를 추가한 방식으로 구현되어있는 것 같아 해당 논문리뷰의 필요성을 느껴 리뷰해 보겠다! 생각보다 유명한 논문이라 놀랐다
배경지식
논문을 읽는데 img resizing에 대한 배경지식이 없어서 힘들었다. 해당 글이 배경지식을 얻는 데 큰 도움이 되었다. https://sanghyun.tistory.com/19 image resizing 함수를 다양한 라이브러리에서 항상 사용해왔지만, polling 등으로 간단하게 이루어지지 않을까 막연하게 생각해왔는데 전혀 아니었다. 해당 글을 통해 여러 가지 보간법이 존재하고 대략 어떤 방식으로 진행되는지 알 수 있었다.
간단히 설명하여 보자면 input 이미지를 하나의 space로 보고 그 공간에서 다시 pixel 들을 resampling 하는 과정을 거친다. (용어에 따라 resampling 말고 interpolation 이라는 용어를 사용하는 것 같기도 하다)
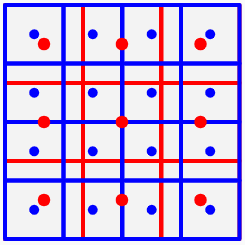
이해를 돕기 위한 그림 점은 pixel 중심 좌표이며 기존 이미지를 하나의 평면 공간으로 보고 다시 sampling을 진행하는 그림이다. 성능이 좋은 resampling을 진행하기 위해서는 저 space를 잘 정의할 필요가 있는데 이때 사용되는 라이브러리마다 다르다. matplot의 경우bicubic interpolation 방식을 사용한다.
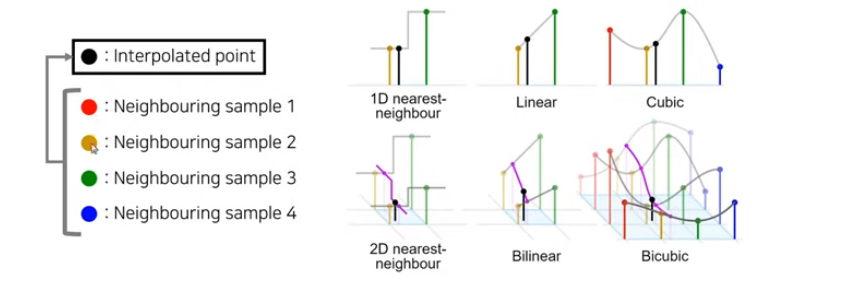
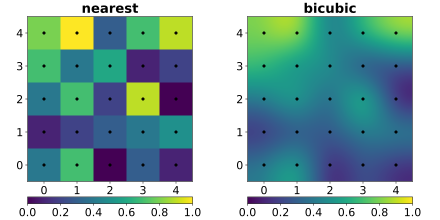
- 이미지 출처 https://sanghyun.tistory.com
bicubic interpolation이 기존 space를 바꿔준 모습 시각화 discrete한 space 에서 continuous space로 옮긴 것을 확인할 수 있다. 저렇게 continuous space에서 sampling을 진행한다면 더욱 정교하게 resizing 된 결과를 얻을 수 있을 것이다. Liif 도 결국 저해상도 이미지를 통해 continuous space 를 정의하는 interpolation 함수를 제안하는 논문임을 인지하니 논문 이해에 많은 도움을 주었다.
intro
이미지를 super resolution으로 변환해주는 여러 딥러닝 기법이 존재하지만, 필요에 따라 자유롭게 resolution을 결정할 수 있도록 해주는 모델은 마땅치 않다. 해당 논문에서는 이를 해결해주는 방법을 제시한다.
- 기존 여러 super resolution model은 output scale 을 임의로 정하기 어려워, 모든 scale에 대하여 좋은 성능의 super resolution 결과를 얻기 위해서는 각 scale에 대응하는 여러 모델을 만들어야 하는 한계가 있다.
- LIIF 는 Neural Implicit Represenation를 통하여 implicit image function 을 사용, 즉 image space를 implicit function으로 정의하여 이러한 한계를 극복한다.
Local Implicit image function
- s : 하나의 픽셀에 대한 RGB 값
- x : Continuous space에서 위치
- z : Latent Code
- θf : neural network의 파라미터
위 간단한 식이 논문에서 제시하는 아이디어의 MLP part의 form이다. MLP model의 input으로 latent code와 continuous space에서의 x quary 좌표(실수값)이 들어간다. 그러면 mlp를 거친 후 해당 위치에 rgb 값이 나온다. 일반적인 interpolation의 과정과 매우 유사하다. latent code가 들어간다, 수학적으로 설계한 함수가 아닌 mlp 가 함수로 사용된다는 차별점 정도만 존재한다고 볼 수 있을 것 같다. 이들에 관한 자세한 내용은 아래 서술하겠다.
먼저 논문에서 말하는 latent code($z^*$)는 무엇일까?
여기서 latent code는 원본 저해상도의 이미지의 pixel 값이다. SR 이 진행된 결과에 비해 pixel 당 더욱 많은 정보량을 포함하기 때문에 이러한 표현을 사용할 수 있다고 언급하였다. 하지만 그냥 원본을 사용하지는 않고 encoder(RDN/EDSR) 을 거친 image 를 사용하는 것 같다. 이러한 과정을 거치면 각 latent code는 이전보다 더욱 많은 local 정보를 내포할 수 있어진다. (이런 구조 때문에 Local implicit function 이라고 한 것일 수도 있을 것 같다)
M 의 의미는 무엇일까?
convention 에 등장하지는 않지만 논문에서는 M의 개념이 자주 등장한다. M은 enoder를 통과한 2d feature map 으로 생각하고 논문을 읽었다. (그냥 low resolution img 인지 enoder을 통과한 low resolution 인지 헷갈린다)
$x_p$ 의 의미는 무엇일까?
$x_p$ 는 더욱 직관적이다. 기존 image interpolation 을 아는 사람들은 이미 알고 있을것 같다? 말 그대로 continuous space에서의 x 위치를 의미한다. Continuous space이기 때문에 당연히 범위 내 실값이라면 모두 가능하다.
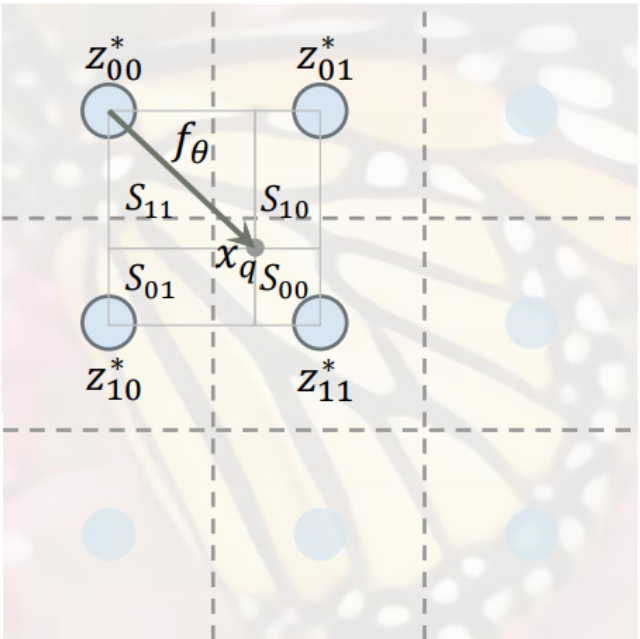
- 이해를 돕기 위한 시각화 (출처 : LIIF paper)
이제 다음 단계로 넘어가자면 앞선 간단한 식 s 의 최종형태는 다음과 같은데(성능향상을 위한 local ensemble이 고려된)
앞선 식보다 조금 복잡해졌지만 겁먹지 말고 하나씩 생각해보자,
$I$
$I$는 continuous space 의 image 이다. 해당 space 에서 한 지점의 rgb값에 대한 quary ($x_q$) 를 표현하는 식이다. 먼저 $x_q$ 로부터 가까운 4개의 $z^*$(latent code)을 구한다.
$v^*$
우리가 원하는 query coordinate $x_q$로부터 가장 가까운 latent code의 좌표다. z는 latent code 값 v 는 latent code의 위치 정도를 의미한다.
$\frac{S_t}{S}$
해당 부분은 이후 모델에 성능을 높이기 위해 제시한 3가지 트릭 중 local ensemble 부분에 등장한다. 위 사진을 본다면 쉽게 알 수 있듯이, 가장 가까운 하나의 latent code 만을 사용한 것이 아닌 $x_q$를 중심으로 각 사각형의 넓이를 구하여 weighted sum 을 한 것이다. 여기서 $S_t$ 가 넓을수록 많은 값을 가지고 오기 때문에 $z^*_t$ 의 반대 방향의 사각형 넓이를 사용한다. 이러한 interpolation 을 거치면 좀 더 부드러운 경계를 갖게 될 것이다.
Enhancing performance
논문에서는 추가적으로 성능향상을 위한 3가지 방법도 제시한다.
Feature unfolding
M의 각 latent code에 대해 feature unfolding을 진행한다고 한다. unfolding 이란 개념을 처음 들어서 조사해본 결과 convolution처럼 움직이며 tensor의 dimension size를 조절하여 원하는 tensor를 얻는 역할을 하는 함수라고 한다. 각 M의 feature 들에 대하여 주변 값에 대한 정보를 더하기 위하여 이러한 과정을 거친 것으로 생각되며 주변 8 feature 의 값을 concat 한다. zero padding 을 사용하였다고 한다. (개인적으로 encoder 도 거치고 추가적으로 unfolding 까지 진행하는 게 좀 의문이긴 하다.)
Local ensemble
앞서 설명하였다.
Cell decoding
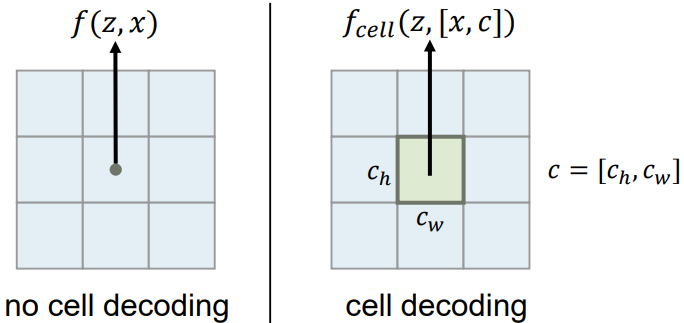
성능향상을 위한 3가지 기법 중 가장 이해하기 힘들었던 부분이다. 기존 f 함수에는 z 와 x 만이 input으로 들어갔지만, cell decoding은 x 뿐아니라 [x, c] 가 함께 들어가게 된다(c 는 query pixel의 normalize 된 image space 에서의 shape 정보라고 해석하였지만 확신은 들지 않는다). 논문에서는 cell decoding 을 사용하는 이유를 대부분의 query pixel이 주변 영역에 대하여 독립적이지 않지만, 기존 방식은 주변 영역을 고려하지 않기 때문이라고한다.
training
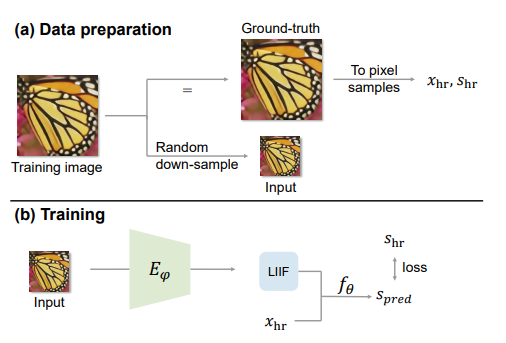
Liif는 self supervised learning 을 통하여 학습되는데 학습 과정은 꽤 단순하다.
- super resolution 에서 random down sampling 한 이미지 획득
- 해당 이미지 encoder 거침 but 크기는 그대로 local 한 특징을 가져간다(일종의 indutive bias를 가져간다고 볼 수 있을까?)
- 해당 feature 와 고해상도의 $x_{hr} , s_{hr}, s_{pred}$ 을 통해 $f_\theta$(MLP) 를 L1_Loss 로 학습 진행(간단!)
- down sampling은 bicubic interpolation 을 사용하여 진행하였다.
- encoder 는 EDSR / RDN 을 비교한 내용이 논문에 등장한다 기회가 된다면 각 encoder도 한번 공부하겠다.
Conclusion
전체적인 모델의 흐름을 보자면 아래처럼 표현이 가능할 것 같다.
저해상도 이미지 들어옴 → feature encoder 를 거쳐 같은 사이즈로 latent code로 이루어진 space M을 구함 → M을 unfold 연산을 통해 더욱 많은 지역 정보를 얻음 → query pixel 위치와(실수값), 가장 가까운 latent code를 중심으로 MLP 를 거침 → 하나의 latent code 만 사용시 부드럽지 않을 수 때문에 가장 가까운 4개의 latent code 에 대해 연산을 진행하며 해당 값은 넓이를 이용하여 weighted sum 을 진행(+ 경우에 따라 cell decoding 도 사용)
마지막 여담으로 논문을 읽고 알게된 점을 간단하게 적어보겠다. nerf와 동일한 implicit 한 방법을 사용하여, 각 데이터마다 별도의 모델이 존재하는 overfitting model 이라고 생각하였는데 implicit 한 방법을 사용하였다고 꼭 overfitting model 이 아니라는 사실이 좀 납득이 안 되지만 그렇다는 것을 알게 되었다. 생각보다 간단한 논문인데도 이해하는데 오랜 시간이 걸렸고 잘못 해석한 부분도 많은 것 같다. 관련 research 를 계속 진행하고 잘못된 내용을 알게 된다면 그때그때 수정하겠다.
+MetaSR 논문에 등장한 방식을 상당수 사용한거 같다. 해당 논문도 시간이 난다면 읽어 보면 좋을 것 같다.
+아직 코드 분석은 해보지 않았지만 해당 방식을 다양한 CV task 에 적용해 볼 수 있을 것 같다는 생각이 든다. 산학프로젝트 진행 중에 이 구조를 사용할 수 있다면 해봐야겠다.
Reference
1) https://sanghyun.tistory.com/21#recentComments
2) https://arxiv.org/pdf/2012.09161.pdf
궁금한 점이 있다면 남겨주세요! 함께 고민해 보겠습니다.