논문리뷰 Implicit LiDAR Network
background
lidar sensor는 높은 신뢰도의 depth 를 얻을 수 있는 장점이 존재하지만 너무 비싼 가격이라는 치명적인 단점이 존재한다. 진행중인 산학 프로젝트에서도 이런 단점 때문에 lidar sensor를 사용할지에 대한 이슈가 있었다. 아무튼 lidar sensor의 가격은 lidar의 resolution 이 높을수록 급격하게 증가하기 때문에 sparse 한 lidar sensor의 depth map을 통해 super resolution의 depth를 추론하는 것은 자율운행 등 lidar sensor을 요구하는 분야에서 상당히 중요한 challenge다.
Intro
앞서 Liif 논문 리뷰에도 비슷한 내용을 다루었듯이 이미지를 Super resolution으로 변환하는 법을 생각해보면 가장 먼저 생각나는 것이 바로 encoder decoder을 이용한 Super resolution 생성이다. 하지만 이는 특정 resolution의 결과만을 얻을 수 있다. 이런 한계점을 넘어 이미지를 continuous domain(space)에서 표현하려는 시도를 한 논문이 바로 Liif 였으며, 해당 논문 또한 Liif 의 아이디어를 기반으로 한여 ILN 이라는 새로운 구조를 제안한다.
기존 Liif를 바로 LiDAR range image에 사용할 수 있지만, 논문의 저자들은 이러한 방식은 몇 가지 문제가 존재한다고 한다.
- 기존 Liif는 low resolution의 pixel 값을 이용한 보정이 아닌, pixel 값을 MLP 이용하여 추정 이후 이 값들을 interpolation 하는 과정을 거친다. (논문에서는 이과정을 새로운 이미지를 만드는 과정이라 명명하는 것 같다) ILN지적하고 이로 인하여 학습에 오랜 시간이 걸리는점을 지적한다.
- 고차원에 공간에서 regression 문제가 되어버린다. (해당 부분은 어떠한 관점에서 이런 설명을 한건지 모르겠다)
- Liif 는 모델 구조상 주변 pixel 값들을 사용하기 때문에 결국 linearly interpolated 한 방식을 사용하기에 sharp edge 가 blur될 가능성이 높다. (아무리 pixel 값을 예측을 잘해도 interpolation w 는 위치에 따라 고정이기 때문에 필연적으로 sharp edge 가 blur 될 가능성을 배제할 수 없다) 첫번째로 지적한 문제와 어느정도 일맥상통하는 부분이 있다.
이러한 특성들이 sharp edge와 빠른 시간 등등이 중요한 lidar task 들과 적합하지 않기 때문에 ILN이라는 새로운 network를 제안한다.
Problem definition and motivation
ILN은 아래와 같은 기존 LIIF와 차이를 갖는다.
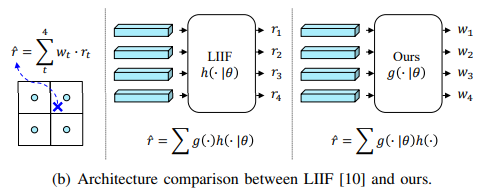
결론만 이야기하자면 기존 interpolation 함수를 만들어 줬다고 생각할 수있다. (interpolation weight 를 학습) 이 시점에서 위 그림만을 보고 이해가 되지 않을 수도 있다. 아래 수식을 따라가며 이해하여 보자
논문에서 $\hat{r}$ 을 예측하는 방법이다. pixel value 지만 rimg 형식이라는 차별성을 두기위해 detection depth 와 같은 용어를 사용한다
$I$ 는 input range image를 의미, $q$는 Liif에서 등장하였던 query point에 상응하는 개념이라 생각하면 된다. 기존 모델과 다른 점은 ILN은 range image의 개념이 등장하기 때문에 lidar의 fov 안에 있는 laser direction $(v,h)$ 을 의미하게 된다, 각각 수직, 수평의 방향 벡터를 의미하지만, 2D 이미지이기 때문에 해당 값을 그냥 pixel 위치로 변환하는 과정을 거칠 것이기 때문에 그냥 pixel 위치라고 생각해도 무리가 없을 것 같다.
기존 Liif 의 수식이다. 자세한 내용은 이전 포스팅 을 보자
해당식을 이논문에서는 아래와 같이 표현한다.
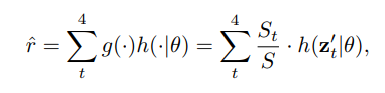
앞서 첨부한 사진과 비교하여 보면 비로소 뭘 하겠다는 건지 이해가 된다. 바로 기존 Liif 의 $ \frac{S_T}{S} $ 부분을 거리에 기반한 단순 넓이를 interpolation w 로 사용하지 않고, 해당 w 를 예측하는 모델을 만들겠다는 것이다.
논문에서 제안하는 식이다. w 를 추정하고 추정한 w 로 interpolation 을 진행하여 최종적인 결과를 얻는 것을 알 수 있다.
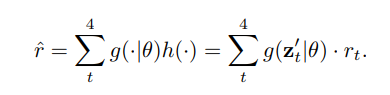
앞서 말한 내용들을 간단하게 정리해 보겠다.
기존방식 implicit function를 통한 새로운 값!!(4개) 예측 후 주변 pixel들이 예측한 값과 거리 기반 interpolation → 논문이 제시한 방법 : 새로운 값 예측을 사용하지않고 origin pixel값(encoder를 거친)사용 기존 거리 기반 interpolation을 implicit function을 사용한 interpolation으로 변화
interpolation weight estimation
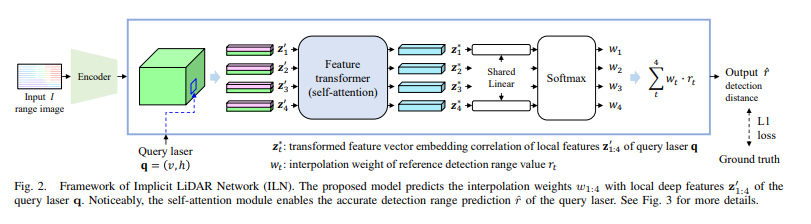
앞선 내용들을 이해하였다면 이후 내용은 더욱 이해가 수월하다. 기존 Liif 구조에 몇가지를 더하였는데 크게 어렵지 않은 내용들이다.
- 먼저 rimg에 대하여 encoder를 적용한다. 해당 부분은 Liif와 같은 encoder를 적용하며, low-resolution rimg로 부터 feature을 얻기 위해 사용한다.
- 1번 과정을 통해 생성된 일종의 feature map에서 얻는 query laser와 latent code(z)를 하나의 $ {z}’ $ 로 변환한다. 이 과정에서 기존 방식과는 다르게 positional embedding 을 사용한다.
- 생성된 $ {z}’ $ 를 이용하여 self attention을 진행하는데 이러한 구조를 사용한 이유가 이해되지 않았다. 완벽하게 이해는 되지 않지만, attention 모델의 특성상 4개의 $ {z}’ $ 중 필요한 정보만을 선택할 수 있고, 이러한 특성을 이용하여 기존 선형적인 특성을 줄여줄 수 있다.
- 위 과정들을 통해 최종적으로 생성된 $ {z}’ $ vector들은 최종 linear layor + softmax를 거쳐 하나의 0~1 사이 확률값이 되고 이를 w 를 이용한 weighted sum으로 최종 detection depth를 예측한다.
Conclusion
위 내용들이 ILN의 전부이다. 너무 어려운 내용이나 수식은 없었으며, 기존에 제시된 여러 기법을 잘 적용하여 좋은 결과를 얻어낸 논문이라고 생각된다. 결과적으로 앞서 언급한 구조를 통하여 빠른 train 속도로 sharp edge를 표현이 까지 가능한 lidar super resolution 에 적합한 모델을 만들었다고 논문은 이야기한다.
진행 중인 산학 프로젝트에 해당 논문을 적용할 예정이고, 코드 리뷰나 후속 게시물들도 계속 업로드 하겠다.
Reference
1) https://sgvr.kaist.ac.kr/~yskwon/papers/icra22-iln/ICRA22_iln.pdf
궁금한 점이 있다면 남겨주세요! 함께 고민해 보겠습니다.